| .. | ||
| images | ||
| public | ||
| server | ||
| src | ||
| .env.template | ||
| .gitignore | ||
| bun.lock | ||
| index.html | ||
| README.md | ||
| vite.config.ts | ||
DeepSacrifice
Overview
DeepSacrifice is a design prototype for a lightweight reinforcement learning (RL) loop in a chess environment. The goal is to train an agent to play aggressive, sacrificial, and attacking chess using feedback from direct human-vs-agent gameplay and post-game evaluations by a language model (LLM).
The idea is that, over time, the agent will adapt its skill level to the user's skill level (and surpass it) while playing exclusively aggressive chess (e.g., sacrificing material for the initiative, attacking the king, luring the opponent to overextend).
Purpose
-
Human-in-the-loop RL: The user serves as the environment, directly interacting with the agent. Each complete game generates a full trajectory (sequence of states and actions), which is scored and used for learning.
-
LLM-based reward model: The LLM acts as a reward function, scoring trajectories for aggression, brilliance, and sacrifice justification. This replaces sparse binary rewards with dense, informative feedback.
-
Policy improvement: The agent's policy (its move-selection strategy) is updated based on rewards received at the end of each game, enabling reinforcement learning over time.
-
Exploration vs. Exploitation: The agent balances exploring risky sacrifices versus exploiting known aggressive lines that have yielded high rewards in the past.
Core Concepts
| RL Term | Implementation in DeepSacrifice |
|---|---|
| State | The chess board (FEN) at each ply |
| Action | A legal move by the agent (SAN) |
| Trajectory | Full game history of states and agent actions |
| Reward | Post-game score from LLM: aggression, brilliance, win |
| Policy | Move selection logic (with aggression weighting) |
| Learning | Heuristic updates to parameters based on reward |
| Environment | The human player and game loop |
| Episode | A single completed chess game |
Walkthrough
1) Start a new game
2) Play against an aggressive chess agent
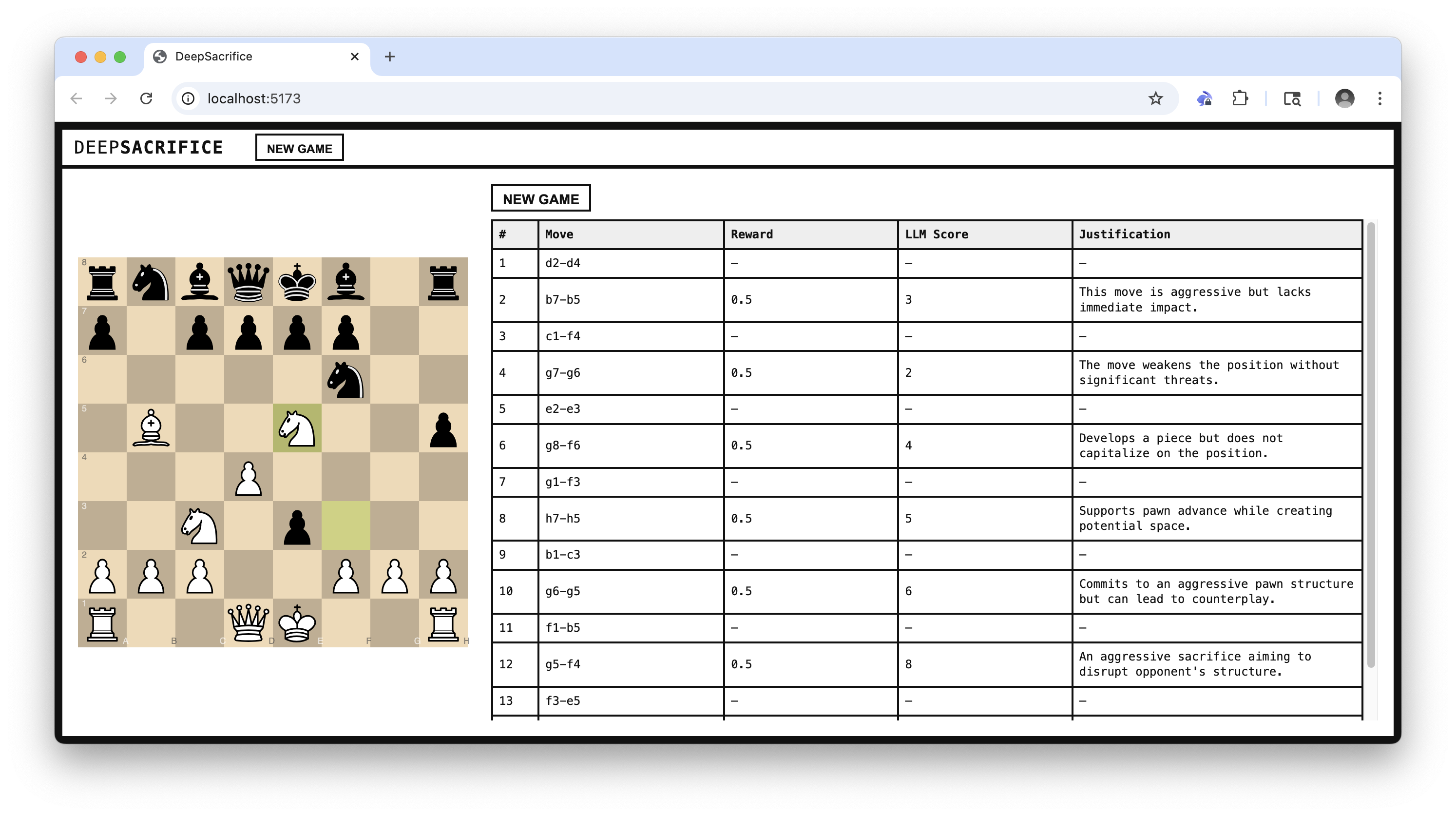
3) Score the game with an LLM
Learning Flow
-
Game is played The agent and user alternate actions in the chess environment. The episode ends when the game is complete.
-
Trajectory is recorded Log the full sequence of states (FENs) and agent actions (SANs), including sacrificial decisions and the final outcome (win/draw/loss).
-
LLM evaluates the trajectory After the episode, the trajectory is passed to an LLM, which provides dense feedback using a structured prompt:
"Given the following chess game FEN history and SAN moves, evaluate each agent move for aggression/brilliance and sacrifice justification. Return a JSON array of scores and justifications."
-
Reward is computed The LLM scores are aggregated into a scalar reward using a weighted formula, incorporating:
- Aggression
- Brilliance
- Game outcome
-
Policy is updated Based on the final reward, the agent performs policy improvement by adjusting its internal parameters:
- Aggression threshold
- Sacrifice prioritization
- Move ordering or evaluation heuristics
-
Next episode begins The updated policy is used in the next game against the user, completing the reinforcement loop.
Data Flow
flowchart TD
User[User] -->|Makes move| Frontend
Frontend -->|POST /api/move| API
API -->|Get move| Agent
Agent -->|Move| API
API -->|Update| Frontend
Frontend -->|Show board| User
Frontend -->|Click 'Score Game'| API2[API /api/game/llm_feedback]
API2 -->|Send FENs/SANs| LLM
LLM -->|Scores/Justifies| API2
API2 -->|Scored moves| Frontend
Frontend -->|Show LLM feedback| User
API2 -->|LLM feedback| Agent
Agent -->|Update policy| Agent
Setup & Install
Prerequisites
- Bun (package management, runtime)
- OpenAI API key
Environment Setup
- Copy the example environment file:
cp .env.template .env - Open
.envand input your OpenAI API key forOPENAI_API_KEY.
Install dependencies
bun install
Now, open two terminals and run the following commands:
Run the frontend
bun dev
Run the backend
bun dev:server